Cloud in der Praxis
Resilienz und Lastverteilung mit RabbitMQ
Verteilte, cloudbasierte Systeme bestehen oftmals aus einer Vielzahl von Diensten. Hinsichtlich der Kommunikation der Cloud-Dienste untereinander bringt dies im Gegensatz zu rein monolithischen Systemen neue Herausforderungen mit sich. Technologisch steht eine breite Palette an Auswahlmöglichkeiten zur Verfügung. Synchrone Protokolle und Standards wie gRPC, SOAP, REST oder GraphQL bieten eine direkte, effiziente Dienst-zu-Dienst-Kommunikation. In vielen Konstellationen kann jedoch asynchrone Kommunikation über Message-Broker die bessere Wahl sein. Dieser Artikel zeigt anhand eines Hands-On-Beispiels, wie sich asynchrone Cloud-Kommunikation mit RabbitMQ realisieren lässt.
Motivation
Mit zunehmender Komplexität eines Systems erhöht sich typischerweise auch die Anzahl der beteiligten Dienste. Bei synchroner Kommunikation muss ein anfragender Dienst (Consumer) auf die Antwort des empfangenden Dienstes (Provider) warten. Dies führt zu einer temporalen Kopplung der Dienste. Die Anfrage kann nur dann erfolgreich sein, wenn beide Dienste gleichzeitig verfügbar sind. Sollte der Empfänger nicht verfügbar sein, muss eine Fehlerbehandlung, wie z. B. eine erneute Übertragung erfolgen.
Diese erneute Übertragung kann durchaus nicht trivial sein, da zu klären ist, wie häufig und z. B. in welchem zeitlichen Abstand diese erfolgen soll. Der schwerwiegende Nachteil ist hier allerdings die Kopplung der Dienste. Wenn auf Consumer-Seite ein Thread pro Geschäftsprozess (z. B. eine Nutzeranfrage) eröffnet werden muss, dann bleibt dieser offen, bis eine Antwort durch den Provider erfolgt ist. Wenn nun der Provider langsamer als üblich antwortet, stauen sich auf Consumer-Seite die Anfragen, und die Anzahl der Threads steigt stark an. Dies kann letztlich zu einer Erschöpfung der Ressourcen führen. Vom Consumer abhängige Dienste können dadurch ebenfalls in Mitleidenschaft gezogen werden: In einem solchen Fall kann es zu kaskadierenden Dienstausfällen kommen.
Um die genannten Probleme zu vermeiden, bietet sich asynchrone Kommunikation per Message-Broker an. Die Datenübertragung und Kommunikationslogik wird in diesem Fall auf die Infrastrukturebene verschoben. Die Dienste sind in diesem Fall nur von der Existenz des Message-Brokers abhängig, aber nicht von der des Consumers - es findet daher eine Entkopplung statt. Des Weiteren muss Kommunikationslogik wie z. B. eine erneute Übertragung, die Priorisierung von Nachrichten oder die Lebensdauer von Nachrichten nicht in jedem Dienst repliziert werden.
Da die Logik in die Kommunikationswege verschoben wird, könnte man an dieser Stelle natürlich Bedenken anmelden: Ein häufig verwendeter architektonischer Ansatz ist “keep your middleware dumb, and keep the smarts in the endpoints” [1, S. 111]. Dieses Prinzip bleibt hier jedoch gewahrt, da die Geschäftslogik in den Diensten selbst verbleibt. Die , ob und in welcher Reihenfolge weitere Dienste aufgerufen werden, verbleibt in den Diensten. Dadurch ist sichergestellt, dass Dienst- und Broker-Deployments weiterhin unabhängig voneinander erfolgen können. Fachliche Details wie Routing-Regeln sollten also nicht in der Konfiguration des Message-Brokers hinterlegt sein.
Im folgenden Abschnitt soll nun RabbitMQ als konkretes Beispiel eines solchen Message-Brokers betrachtet werden.
RabbitMQ
Für dieses Beispiel wurde RabbitMQ gewählt, da dieser Broker bei GONICUS selbst bereits in Produktivsystemen eingesetzt wird. Außerdem zeichnet sich RabbitMQ durch die Unterstützung einer Vielzahl von Protokollen aus - sowohl nativ (AMQP 0-9-1, AMQP 1.0), als auch durch Plugins (MQTT, STOMP, etc.). Um ein möglichst praxisnahes Beispiel zu geben, beschränkt sich dieser Artikel auf das AMQP 0-9-1 Protokoll [2].
Bei asynchronem Messaging wird zumeist zwischen zwei Kommunikationsmustern unterschieden: Point-to-Point (Queue) und Fanout-Message-Distribution (Topics). Bei einer Point-to-Point-Kommunikation wird eine Nachricht immer an genau einen Subscriber der Warteschlange (Queue) versandt. Bei mehreren Subscribern wird ein Subscriber aus dem Pool ausgesucht, was für Load-Balancing Zwecke genutzt werden kann. Dieser Fall wird als Competing-Consumer-Pattern bezeichnet.
Im zweiten Fall, also bei der Fanout-Message-Distribution, wird eine Nachricht an alle Subscriber, die sich für ein bestimmtes Thema (Topic) interessieren zugestellt. Hier kann die jeweilige Nachricht unabhängig und parallel durch alle Subscriber prozessiert werden. [3]
Zu beachten ist, dass sich die Nomenklatur bei RabbitMQ von klassischen Systemen etwas unterscheidet: Topic bezeichnet dort nicht wie bei anderen Systemen ein übergeordnetes Konzept, sondern einen speziellen Exchange-Typ [4].
Hands-On
Nach den einleitenden Worten soll nun der praktische Teil gezeigt werden. Dazu ist auf GitHub ein Demo-System hinterlegt. Das Demo-System simuliert eine Task-Queue-Architektur, bei der Arbeitspakete durch einen Producer-Dienst erstellt werden, welche dann von einem Worker-Pool abgearbeitet werden. Ein Worker kann dabei eine bestimmte Zahl unbestätigter Nachrichten aufnehmen (Prefetch Count), die durch den Message-Broker zugewiesen werden. Das kann z. B. auch nur eine Message sein.
Während der Verarbeitung durch den Worker können weitere eingehende Nachrichten dann weiteren Workern zugeordnet werden. Sobald ein Worker die Verarbeitung der aktuellen Nachricht gegenüber dem Broker bestätigt hat (Consumer-Ack), kann dem Worker die nächste Nachricht zugeordnet werden. Als Broker wird ein Cluster aus drei RabbitMQ-Instanzen verwendet. Das Monitoring des Message-Bus kann durch das RabbitMQ-Management-Interface oder durch eine ebenfalls hinterlegte Grafana-Instanz erfolgen. Abbildung 1 gibt einen Überblick über die Struktur der Dienste.
Abb. 1: Container-Diagramm des Demo-Systems mit Kommunikationsflüssen.
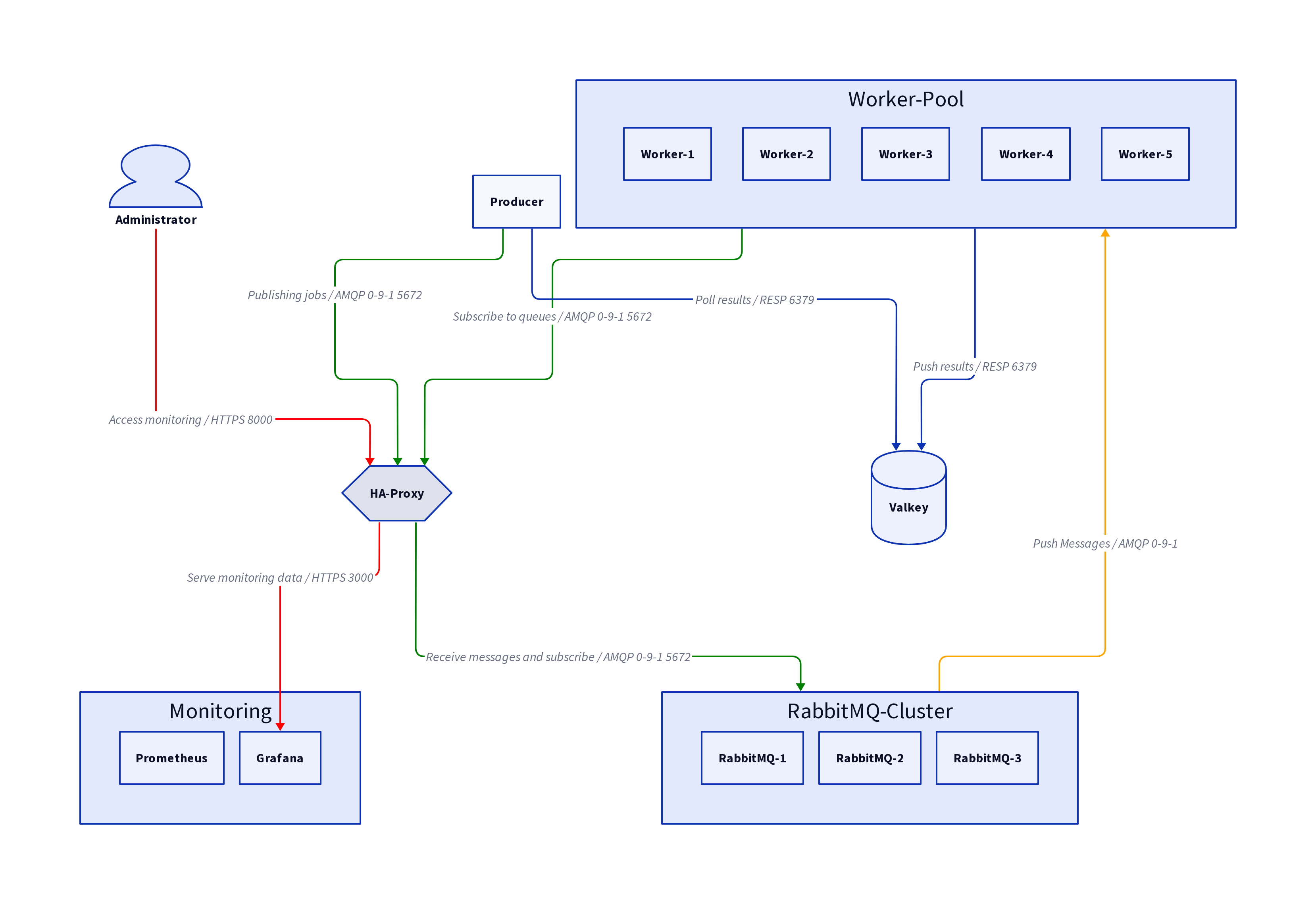
Zusätzlich dient eine Valkey-Instanz als Result-Backend. Ein Result-Backend ist im Competing-Consumer-Pattern nur erforderlich, wenn der Rückgabewert eines Tasks relevant ist. Tasks die z. B. nur zu einer Datenbank-Änderung führen, können die Verarbeitung auch ohne Rückgabewert abschließen. In der Demo wird das Result-Backend genutzt, um die Verarbeitungsdauer der Tasks zu messen.
Zum Starten der Demo muss initial das Grafana-RabbitMQ-Dashboard bezogen werden,
welches nicht mit der Demo mitgeliefert wird. Anschließend kann die Demo mittels
docker compose up gestartet werden.
curl -L https://grafana.com/api/dashboards/10991/revisions/15/download -o config/grafana/dashboards/rabbitmq-dashboard.json
docker compose up
Durch Strg+c lässt sich die Demo wieder beenden. Sobald alle Dienste gestartet
und initialisiert sind, können Tasks generiert werden:
docker compose run --rm --build client --time 400 0.1
Der Client (Producer) verschickt im obigen Beispiel 400 Tasks an die fiktive Queue
user.account.create.demo-service, die jeweils eine
Verarbeitungsdauer von 0.1 Sekunden haben. Die Bearbeitung dieser Tasks durch die 5
Worker sollte ca. 9 Sekunden in Anspruch nehmen. Bei dieser Queue handelt es
sich um eine in der RabbitMQ-Nomenklatur als classic-queue bezeichnete Queue.
Diese Art von Queue hat schwächere Garantien hinsichtlich der Ausfallsicherheit,
da Nachrichten nicht unter den Cluster-Nodes repliziert werden, und stets nur auf
einem einzigen Node gespeichert werden. Durch Hinzufügen des Flags --quorum zu
obigem Befehl können Nachrichten über eine quorum-queue veröffentlicht werden:
docker compose run --rm --build client --time --quorum 400 0.1
Der obige Befehl erstellt Nachrichten für die Queue
payment.invoice.create.demo-service. Quorum-Queues verbessern die
Ausfallsicherheit, da diese auf allen Cluster-Nodes repliziert werden. Die
Domain payment wurde hier als Beispiel gewählt, da zahlungsrelevante Daten
typischerweise einen hohen Schutz vor Nachrichtenverlust erfordern.
Eine Übersicht über die Nachrichten-Topologie wird in Abbildung 2 gezeigt.
Abb. 2: Nachrichten-Topology des Demo-Systems.
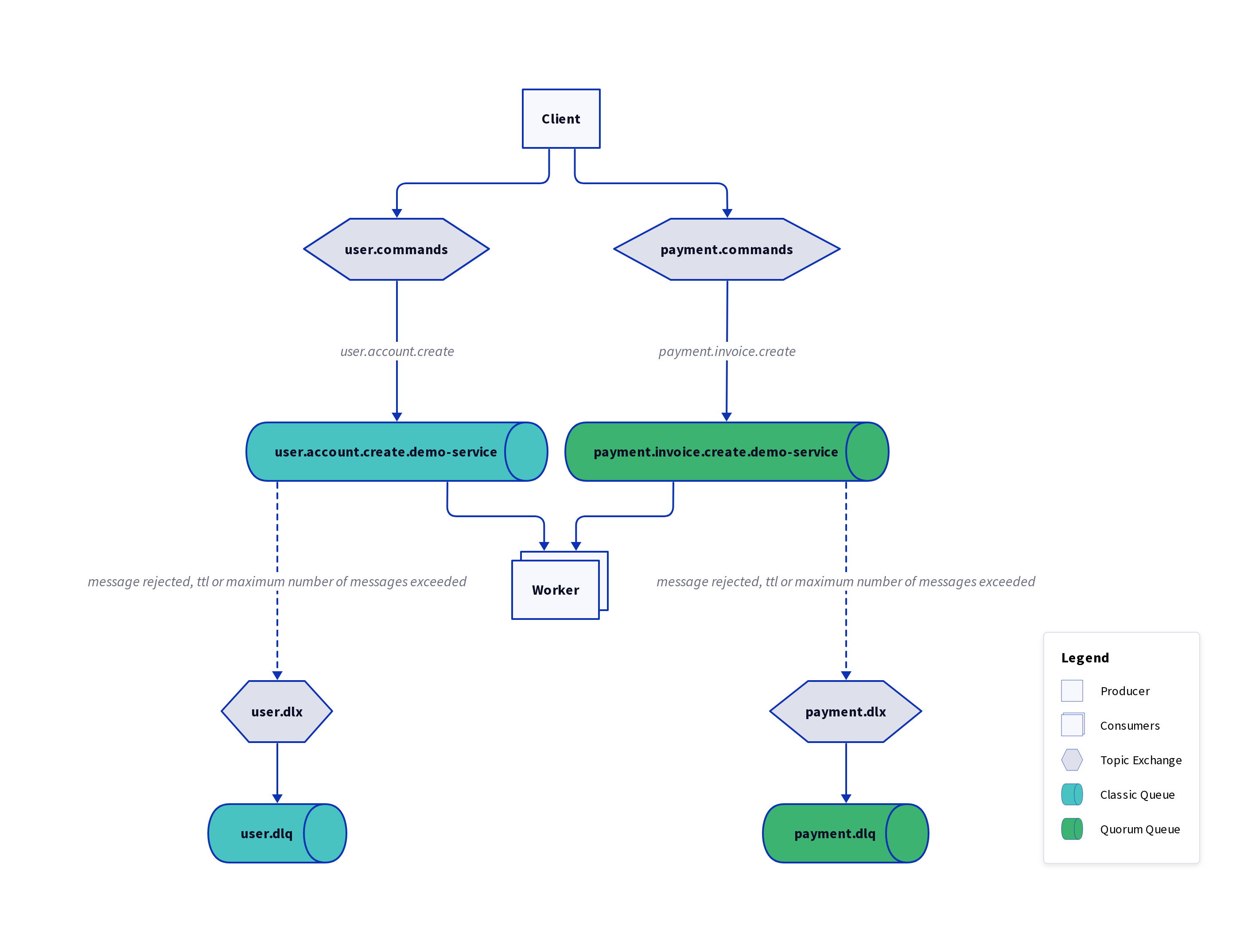
Zusätzlich zu den beiden bereits genannten Queues zeigt die Abbildung die
zugehörigen Exchanges, sowie die Dead-Letter-Queues user.dlq und payment.dlq.
Exchanges nehmen Nachrichten entgegen und verteilen diese anhand festgelegter Routing-Regeln. Einem Exchange können mehrere Queues zugeordnet sein. Anhand der Routing-Regeln werden Nachrichten dann an eine, einen Teil, oder an alle Queues vermittelt.
Ein dead-lettering erfolgt, wenn z. B. die Lebensdauer (TTL) der Nachricht überschritten wurde. In diesem Fall erfolgt eine Vermittlung an den jeweiligen Dead-Letter-Exchange (DLX), welcher die Nachrichten dann den Dead-Letter-Queues (DLQ) zuordnet. Prozesse, die auf Benutzerseite ohnehin nach einigen Sekunden in ein Timeout laufen, erfordern in der Regel eine recht kurze TTL, während z. B. die Erstellung einer Rechnung eine längere Lebensdauer haben kann, um resilienter gegen Dienstausfälle zu sein. Wenn nun eine große Anzahl Nachrichten auf einen Schlag veröffentlicht wird, kann dies kurzfristig die Kapazität der vorhandenen Dienste übersteigen:
docker compose run --rm --build client --time --quorum 10000 0.1
Da die Arbeitspakete durch den Broker in eine längere Queue übersetzt werden, verringert sich die Gefahr einer Ressourcen-Erschöpfung. Die Dienste erhalten weiterhin eine limitierte Anzahl an Arbeitspaketen. Lastspitzen können somit durch den Einsatz eines Message-Brokers geglättet werden. Zusätzlich besteht die Möglichkeit, das System unterbrechungsfrei zu skalieren. Durch den folgenden Befehl wird die Anzahl der Worker auf 20 skaliert:
docker compose up --scale worker=20 -d
Die Worker verbinden sich automatisch mit dem Broker und beginnen mit der
Abarbeitung von Messages sobald die Verbindung etabliert ist. Dies lässt sich
wahlweise durch Grafana unter http://127.0.0.1:8000/grafana oder das
RabbitMQ-Management-Interface unter http://127.0.0.1:8000/rabbitmq
nachvollziehen. Da es sich um eine lokale Demo handelt, ist admin jeweils als
Benutzername und Passwort hinterlegt. Ausschnitte aus den Grafana- und RabbitMQ-Schnittstellen sind in den folgenden Abbildungen dargestellt:
Abb. 3: Grafana-Darstellung der durch Worker verarbeiteten Messages pro Sekunde.
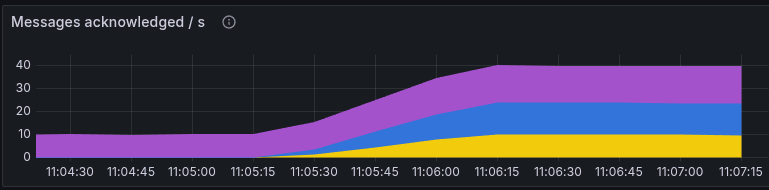
Abb. 4: RabbitMQ-Darstellung der an Worker zur Verarbeitung ausgelieferte Messages pro Sekunde.
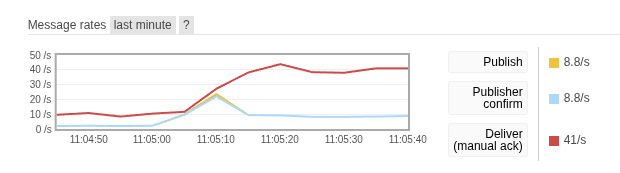
Die Vervierfachung der Worker-Anzahl ist in den beiden obigen Abbildungen gut
durch eine knapp vervierfachte Anzahl übermittelter und verarbeiteter Messages zu
erkennen (nach 11:05). An dieser Stelle könnte natürlich argumentiert werden,
dass auch mit einem vor die Worker geschalteten Load-Balancer ohne Broker
ähnliche Skalierungseigenschaften realisierbar wären. Bei einem Down-Scaling -
wenn also Worker terminiert werden - können durch den Broker nicht vollständig
verarbeitete Nachrichten anderen Workern erneut
zugeteilt werden. Bei einer Load-Balancer-Lösung müssten solche und weitere
Eigenschaften selbst implementiert werden.
Da der Message-Broker damit ein Teil der Infrastruktur wird, sollte dieser
möglichst zuverlässig und “entspannt” seinen Dienst verrichten. Daher
erfordert gerade diese Komponente ein hohes Maß an Zuverlässigkeit.
Monitoring-Möglichkeiten sind unerlässlich, um Fehler zu
entdecken und zu analysieren. Die Demo enthält daher die zuvor genannten
Möglichkeiten für Monitoring per Grafana- oder über das
RabbitMQ-Management-Interface. Außerdem kann unter
http://127.0.0.1:8000/haproxy ein Dashboard mit statischen Informationen des
HAProxy eingesehen werden. Benutzername und Passwort sind in diesem Fall wieder
admin.
Durch den Worker-Pool ergibt sich neben der Load-Balancing-Eigenschaft auch eine bessere Resilienz gegen den Ausfall einzelner Worker. Je nach System kann auch eine erhöhte Resilienz gegen den Ausfall von Broker-Instanzen erforderlich sein. Im vorliegenden Demo-System bilden drei RabbitMQ-Instanzen einen Cluster. In realen Systemen sollten diese Instanzen idealerweise auf unterschiedliche Server-Nodes verteilt werden. In einem Kubernetes-Deployment könnte dies über Pod-Anti-Affinity oder Topology Spread Constraints realisiert werden.
Die Cluster-Informationen werden bei einem RabbitMQ-Cluster gleichmäßig auf allen
Instanzen repliziert mit Ausnahme der Queues [5]. Die Daten der zuvor erwähnten
Classic-Queues sind jeweils nur auf einem der Cluster-Nodes vorhanden - ein
Datenzugriff ist aber dennoch über alle Nodes möglich. Der eigentliche
Speicherort bleibt somit für Producer und Consumer transparent. Bei der Verwendung
von Quorum-Queues sind die Daten hingegen über die Cluster-Nodes verteilt. Die
Verteilung der Hosts der Queues kann über die Queue-Übersicht unter
http://127.0.0.1:8000/rabbitmq/#/queues eingesehen werden (Abbildung 5).

{kind=link}
Abb. 5: Übersicht der RabbitMQ-Queues im Management-Interface.
In der obigen Abbildung ist in der Node-Spalte neben der Quorum-Queue
payment.invoice.create.demo-service ein +2 zu erkennen.
Zum angegebenen Queue-Leader rabbit@rabbitmq-2 gibt es in diesem Fall noch
zwei weitere Nodes (Follower), welche die Queue-Daten replizieren. Sollte der
Node mit dem Queue-Leader ausfallen (in diesem Fall rabbit@rabbitmq-2),
wird über den Raft-Consensus-Algorithmus ein neuer
Queue-Leader bestimmt. Die Queue fiele dann nur für den Zeitraum der
Leader-Election aus. Die Classic-Queue user.account.create.demo-service würde
bei einem Ausfall des Nodes rabbit@rabbitmq-2 in den Status down wechseln
und wäre erst wieder verfügbar, sobald der Node wieder verfügbar wäre.
An dieser Stelle sei noch der Hinweis erlaubt, dass das rabbitmq-2 unterschiedlich
interpretiert werden muss: rabbit@rabbitmq-2 ist ein RabbitMQ-Node und rabbitmq-2
bezeichnet den Host. Der RabbitMQ-Node bezieht sich auf den Server-Prozess, während der
Host in diesem Fall ein Container ist. Üblicherweise ist aber ein Node auch
genau einem Host zugeordnet, weshalb die Begriffe oft sprachlich gleichgesetzt
werden.
Fazit
Asynchrone Kommunikation per Message-Broker kann ein geeignetes Mittel sein um die Ausfallsicherheit und die Skalierbarkeit eines Systems zu verbessern. Anhand des Demo-Systems wird deutlich, dass Queues zur Vermeidung von Last-Spitzen eingesetzt werden können. Prefetch und Consumer-Acknowledgement ermöglichen in diesem Fall die Regulierung der Anfragen an Consumer-Dienste.
RabbitMQ im speziellen bietet mit Classic- und Quorum-Queues unterschiedliche Queue-Modelle, welche je nach Verfügbarkeits- und Durchsatz-Anforderungen gewählt werden können. Diese bieten die Möglichkeit Dead-Lettering und Retry-Strategien gezielt auf Broker-Ebene zu hinterlegen, um so eine Fokussierung der Dienste auf die jeweilige Geschäftslogik zu ermöglichen.
Neben dem hier gezeigten Einsatz des Competing-Consumers-Patterns können mit RabbitMQ mittels der flexiblen Routing-Mechanismen weitere Nachrichten-Topologien wie Publish-Subscribe per Fanout-Exchange, oder selektives Routing per Topic-Exchange realisiert werden. In Cloud-Infrastrukturen kann asynchrone Kommunikation somit ein effizienter Baustein zur Lösung verschiedenster Problemstellungen wie Lastverteilung, Broadcast oder Nachrichten-Filterung sein.
Referenzen
[1] S. Newman, Building Microservices: Designing Fine-Grained Systems, 2nd ed. Sebastopol, CA: O’Reilly Media, 2001, p. 165.
[2] AMQP Working Group, “Advanced Message Queuing Protocol: Protocol Specification, Version 0-9-1,” AMQP Working Group, Nov. 13 2008. [Online]. Available: https://www.amqp.org/specification/0-9-1/amqp-org-download [Accessed Nov. 25, 2025].
[3] J. Higginbotham, Principles of Web API Design: Delivering Value with APIS and Microservices. Boston, MA: Addison-Wesley Professional, 2022, pp. 167-168
[4] Broadcom, “Exchanges - Topic,” rabbitmq.com. (n.d.). [Online]. Available: https://www.rabbitmq.com/docs/exchanges#topic [Accessed Nov. 25, 2025]
[5] Broadcom, “Clustering Guide - What is Replicated,” rabbitmq.com. (n.d.). [Online]. Available: https://www.rabbitmq.com/docs/clustering#overview-what-is-replicated [Accessed Jan. 20, 2026]